Summary
The issue we addressed in this project is determining how long a Northwestern IT support request
will take to complete at the time of its creation.
Motivation
Everyday support desks all over the world support millions of users. Each of these users presents
their own unique problem and wants to know how long it will take for this problem to be solved.
This presents a challenge to the help desk staff who cannot provide accurate estimates for every issue.
We propose the use of machine learning techniques in order to provide a prediction for how long
an issue will take to complete at the time of creation.
Implementing these predictions will allow for helpdesk staff to not only provide users with a
more accurate estimate of when their issue will be resolved but could also help identify any possible
bottlenecks that could be avoided or made more efficient to provide better service. For example maybe
we might notice a support group which takes a long time to process tickets because they are receiving
too many issues which might suggest they are short staffed.
Methodology
Our features are attributes of the ticket, such as date and time submitted, its categorization, etc.
We trained our data using a variety of different machine learning algorithms, focusing on algorithms which provided rules.
We then compared the accuracy of these algorithms using 10-fold cross validation on each.
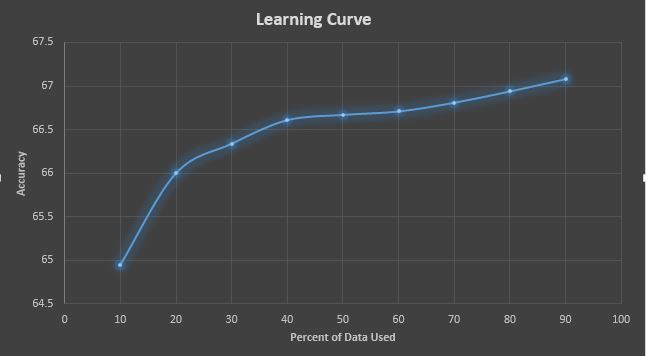
We found the algorithms that yielded the highest accuracy to be the J48 decision tree and IBk Nearest Neighbors Algorithms and fine tuned their parameters to get the highest accuracy. Figure 1 shows the learning curve for the J48 algorithm on our training instances.
We then used these tuned algorithms and ran them against a held out test set to provide the results below
Figure 1:The learning curve produced by the J48 Decision Tree Algoritmh on our data
Results
Using the J48 learning algorithm the best accuracy we achieved was 66.5%. This accuracy is not as high as we hoped to achieved
and we believe there are several reasons for that. First of ou 8690 instances about 63% were in the category of "12 hours or Less"
While the rest of the instances were split among 10 categories, along with this we were missing key attributes including who worked on the issue and what support tools were used. Despite this we were still able to garner some useful information from our decision tree.
Looking at the top decision attributes within the tree we found the most important attributes are whether the ticket was assigned to the main support center or elsewhere, and if the ticket was submitted during a weekday or the weekend. We also found that issues regarding "Our Northwestern" tend to take longer to resolve which is something worth investigating to see if the efficiency of such issues can be improved.